Advanced Web Security: Request Smuggling
28 Sep 2020The Advanced Web Security series looks beyond the OWASP Top 10 web application security risks. For the full list of articles in this series, visit this page.
Today’s web applications and systems are more complex than ever before. While servers should always send data to users over HTTPS, the usage of HTTPS does not guarantee that the data sent from the web server will be received only by the correct recipient. This may be surprising to hear, since in many minds HTTPS equals a green lock symbol which means everything is secure, right? Research from the past year shows otherwise! Request smuggling is a technique that allows a malicious user to receive server responses intended for other users of a web application. This type of attack makes it ever more important that web applications are designed to NOT send sensitive account data to the user (such as the user’s plaintext password, government ID information, payment details, etc.) and reinforces the importance of defense-in-depth. To reiterate, if a web application transmits sensitive account data back to the user, there is an opportunity for a high impact request smuggling attack - HTTPS will not provide protection against this risk.
What is request smuggling?
Every so often, a new attack surface is investigated in the world of web applications, and the result is that high impact vulnerabilities are discovered to impact a large number of websites. In my opinion, this was previously the case with SSRF (server-side request forgery) a few years ago, and I would argue that request smuggling did this in 2019. While James Kettle, the researcher who popularized the vulnerability, humbly decided to remove his research from eligibility in the main PortSwigger Top 10 web hacking techniques of 2019 competition, request smuggling (specifically the HTTP Desync attack variant) easily won the “community favourite” category, indicating that the security community thinks of this attack vector as an important research development. The way that request smuggling works requires thinking about a web application as more than a single web server. Instead, the results of a web application are the sum of all the servers in between your browser and the backend server, and this includes the frontend server (i.e. reverse proxy). Request smuggling targets the fact that the front-end and back-end of the application both handle HTTP requests from users, but it is possible that they handle the requests in slightly different ways due to implementation differences in different code bases. Specifically, request smuggling exploits a difference in how HTTP requests end, which varies based on the “Content-Length” header and the “Transfer-Encoding” header. Due to this issue, we can encounter a scenario like the one shown in the diagram below (borrowed from the request smuggling section of the excellent PortSwigger Web Academy). At a high level, a possible result of this vulnerability is that the backend server may return the response for a web application victim user to a malicious user, potentially exposing details about the victim user to the malicious user.
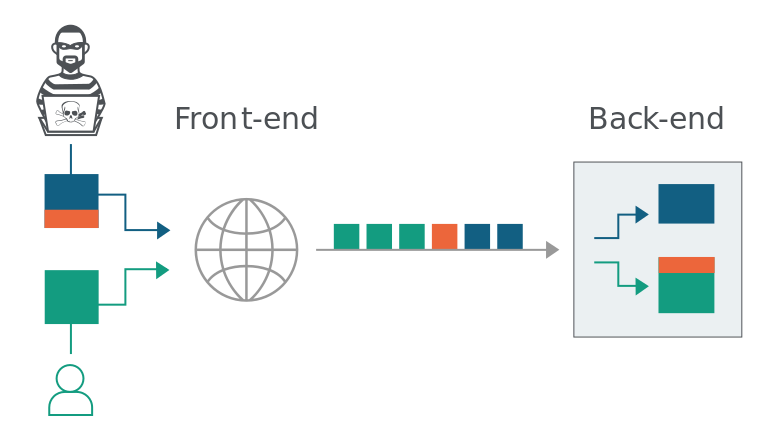
How does request smuggling really work under the hood?
I can’t claim to understand this attack better than the PortSwigger team that did this research in the first place, and therefore will defer to PortSwigger’s explanation for the deeper details of this attack. At the same time, I can try to provide a briefer explanation that may approach the topic from a different angle.
A web application’s frontend frequently takes incoming requests from users and forwards them to the backend over a single TLS connection. The frontend and backend usually are running different software, and certain edge cases of the HTTP/1.1 protocol are implemented differently in different software packages. A malicious user can exploit these different implementations by crafting a HTTP request that is understood one way by the frontend server and a second way by the backend server. Usually this is done by creating a HTTP request with a request body that contains a header that looks like the start of another HTTP request. The server might take this header information and append it to the following HTTP request (one that the malicious user did not send), and effectively inserting a request into another user’s HTTP session (and therefore unaffected by HTTPS security, because this occurs on the server side after HTTP requests are decrypted). While HTTP request smuggling is usually performed using a POST request, since the body of the POST request is used in the exploit process, this detailed request smuggling writeup from the Knownsec 404 team shows a GET request can also perform request smuggling. While it might be possible to consider request smuggling on its own a form of reverse proxy bypass, the impact changes a lot when the server is using a web cache, has internal APIs, or provides other targets.
How can a penetration tester exploit request smuggling?
There are several options to exploit request smuggling, but if you’re not in a rush, I am currently in favor of exploiting this issue manually, at least at first. This provides a deeper understanding of how the server counts the Content-Length value, and how to build a HTTP request in the exact manner needed to exploit the server in the manner you intend. One tip based on a mistake I overcame: when modifying the Content Length, a newline counts as 2 characters (/r/n). However, once you grasp how this vulnerability works, you no doubt will want to speed up the process. Burp Suite has a request smuggler extension, or you can use the turbo intruder Burp extension for more heavy duty testing. Outside of Burp Suite, this tool named “smuggler” is my preferred choice, and I don’t think there are currently many competing off-the-shelf tools. It may be possible to use curl or ncat based on this follow-up comment from James Kettle in a bug bounty report to the DoD, but this doesn’t appear to be a common method (this post was the only instance I found of using ncat for request smuggling).
How to defend against request smuggling?
The easiest approach for small-scale web applications is to remove any CDN, reverse proxy, or load balancers! However, such a simplifying measure is impractical for larger web applications, who rely on these added complexities for increased performance, so the following ideas are commonly considered other mitigation strategies:
- Use HTTP/2 for connections to the backend: the root of the request smuggling vulnerability is ambiguity in HTTP/1.1 RFCs. The newer HTTP/2 protocol resolved the problematic ambiguities.
- Reconfigure frontend/backend communication to avoid connection reuse: Request smuggling relies on confusion about the division of multiple HTTP requests in a single connection. If these HTTP requests are each in a separate connection, there would be no confusion about where each HTTP request starts and ends.
- Use frontend and backend software that rely on the same HTTP request parsing: Request smuggling occurs because different software implementations in the frontend and backend handle ambiguous HTTP/1.1 edge cases differently. If the frontend and backend handle each HTTP request in the same manner, either because both the frontend and backend use the same software or close examination reveals consistent handling of the relevant headers in both pieces of software, then the frontend and backend will not handle HTTP requests in different ways.
References
James Kettle’s excellent research on the topic: https://portswigger.net/research/http-desync-attacks-request-smuggling-reborn
Portswigger Web Academy Request Smuggling labs: https://portswigger.net/web-security/request-smuggling
defparam’s Smuggler standalone Python tool: https://github.com/defparam/smuggler
Portswigger’s request smuggling Burp extension: https://github.com/PortSwigger/http-request-smuggler